
I recently started a Bitcoin and cryptocurrency course in Coursera which I’ve been really enjoying so far (it’s free, if anyone is interested). I wanted to take a moment to talk about one of the programming assignments I was given based on coming to a consensus in a network. If you’re working on this course, I think it’s fine to read about this post to help understand a little about the assignment, I know I was a little lost at times. However, as I will talk about my solution at the end, which I’ll preface with warnings, I’d suggest reading the solution section once you’ve attempted it yourself.
Before that though, I wanted to talk about who linked me to the course - Haseeb Qureshi.

He’s most well known for his post on Negotiating job offers, which does a great job of demystifying the often stressful salary negotiation process. It’s a post I think everyone would benefit from reading. In short, he’s an ex pro poker player, who decided to become a software developer, worked for AirBnB for a while and is now exploring cryptocurrencies, blockchain and the new world of decentralised finance (or DeFi). I found the Coursera link in a post where he lists what things he’d recommend a developer study if they’re interested in learning more about cryptocurrencies, blockchain, Ethereum etc.
Consensus Network Assignment
The assignment tasks students with writing code for the behaviour of nodes in a simulated network, which must ultimately come to consensus - agreement on a set of transactions. At the start of the simulation, each node is initialised with a few random valid transactions and a list of which nodes it follows. Each round, every node has a chance to share transactions with those nodes that follow it and receive all transactions suggested by those it follows. After a fixed amount of rounds, the nodes share their final set of transactions. Success is measured on how many nodes agree on the same set of transactions and how large the set is.

All this sounds easy enough, if the nodes simply accept all transactions and send everything they know about, given enough rounds they should reach consensus right? Ah ha! But what if we introduce malicious nodes which are intentionally trying to break consensus in the network? The assignment calls for students to write code for compliant nodes, which are as resistant as possible to any malicious nodes in the network which are intentionally trying to confuse things.
As complex as the above simulation sounds, it’s actually expressed in a surprisingly small amount of code - the simulation file is only a little over 100 lines of code. The simulation can be modified by tinkering with initialisation values for graph connectedness, percent of malicious nodes, amount of initial transactions distributed and the number of rounds it runs for. Transactions are simplified to an Integer, which represents their ID.
Malicious nodes

The code for the malicious nodes given to students is mostly empty, presumably because if we knew exactly how they were behaving it would be a lot easier to fight them. Which means it’s left as an exercise for the student to come up with ideas on how a node might intentionally cause confusion in the network. This means it actually becomes a fun cat and mouse game, typical for cryptography, where you write progressively more sophisticated evil actors and then switch to writing code for ways to remedy that behaviour.
At the start of the simulation, 500 transactions are randomly generated and then randomly distributed to all nodes. My first thought then, was that the malicious nodes could simply distribute invalid transactions throughout the network. When I tested this though, I noticed that it didn’t seem to have any detrimental effect. It wasn’t till I read the simulation code more thoroughly that I realised - all invalid transactions suggested by nodes are filtered out! Wait really? But then, if malicious nodes can only distribute valid transactions, what could they possible do to ruin consensus?
It wasn’t until I checked the forums that I discovered what it was - the malicious nodes can wait till the end of the simulation to distribute their transactions. As it takes a few rounds for every transaction to propagate through the network, if you introduce new transactions towards the end, only some nodes will have a chance to see these new transactions.
Warning - the next section will discuss the solution. If you want to try the assignment, go take a look at solving it before reading this.
Building a resilient node

My initial malicious node implementation was simply to be silent right up until the final round, where it sent out all its initial transactions. I then countered this in the compliant nodes by ignoring any nodes it followed who were sending it less than 10% of the average transaction count. This would at least force the malicious nodes to distribute most transactions they saw, if they wanted to remain undetected.
So, malicious nodes would then distribute all transactions, right up until the final round where they would add the initial list. A simple counter then was to have the compliant nodes ignore any new transactions they saw in the final round.
Instead of waiting right till the final round then, malicious nodes would start to release their transactions one by one in the final few rounds. To maximise effectiveness, they would save only the transactions they hadn’t seen anyone else distribute in the network, to ensure they were new. As the nodes are initialised with a random amount of transactions, this could lead to them starting to distribute these transactions anywhere from about 8 rounds to 1 round to go. When running with only 10 rounds then, this was a great source of confusion for the compliant nodes.
This then got me thinking about what I considered was probably a major point to learn in the assignment - tracking how many votes or confirmations each transaction has had is useful, i.e. how many times have they been seen. If newer transactions are introduced later, they won’t have had as much of a chance to propagate to all nodes, meaning they will have less confirmations for those that have seen them. So then, we can then filter out transactions which don’t meet a certain threshold level of confirmations. I found that a fixed value for this didn’t quite work so well, as some nodes were much better connected than others, meaning the less connected nodes might choose to ignore transactions others considered well distributed. So I chose to ignore transactions below a certain percentage of the average confirmation count for the other transactions (considering now, a better approach would probably be using standard deviations instead).
Ok computer - find me the solution
But what percent of the average worked best? I initially tried a few values to see the results, but as it varied a lot, I decided to get a little more scientific. I ran the full simulation a number of times, each time reporting the ‘error value’ - the amount of compliant nodes who weren’t part of consensus and averaged this out. It seemed like something in the range of 60-70% was a good value, but I thought instead of me running this over and over again, I’d use some Simulated Annealing to have the computer solve the problem for me.
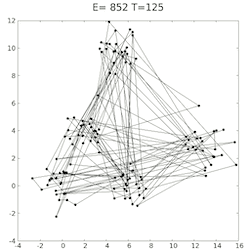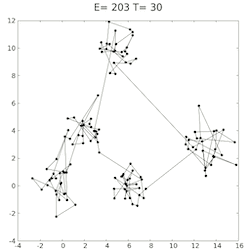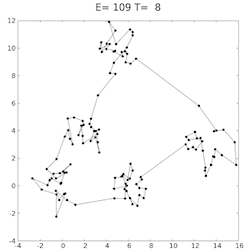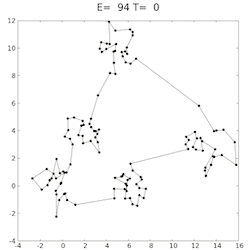
The approach I took then, was to start with 60%, then run the simulation 100 times, get an average and compare to the last loops average - if it was getting lower, continue in the same direction by 1%, if not switch directions and head back by 1%. Unfortunately, there was a lot of variance in the average error, even at 100 simulations. But as 100 iterations already took a few minutes, increasing this right from the start didn’t make sense. I then decided to start off at 100, and each time the direction changed, increase the iteration count by 50. If the variance would was too high at some point then, it would slow it down until it was more confidently heading in the right direction.
Which worked better, but to be honest, as fun as it was creating this, I sort of lost patience after a few hours and got a good enough result of 68%.
Submitting the solution
When I first picked up this assignment, I was curious to understand how effective the malicious nodes were and decided to submit what I considered the default or empty solution - the compliant nodes simply distributed everything they saw. The first time I submitted this, the marking program ran out of memory… Considering this was probably the simplest solution you could come up with, that didn’t exactly fill me with hope. I resubmitted the exact same solution and was encouragingly rewarded with a mark of 80%. Oh… ok… that’s great. The pass mark is 60%, so apparently with essentially zero consideration of strategy, I have completed the assignment with distinction.
When it came to the point where I submitted the above solution I discussed, the marker again ran out of memory. Assuming this was a common problem, I attempted to resubmit 5 times, but with no luck. I finally resorted to stripping the submitted solution back to simply ignoring the last few rounds, which rewarded me with a 91%. At that point I’d lost faith in the marking process and stopped there. I figured I’d worked on the assignment long enough that I understood the essential principles.
Summary
NOTE: As a quick side note, Bitcoin solves the consensus problem a different way altogether, through it’s proof-of-work algorithm and the accepted principle that nodes should always extend the longest known chain. If a malicious actor wanted to have their say in what transactions are processed, they’d need to obtain a majority of the computing power in the entire bitcoin network, in something called a 51% attack. Thankfully this is unlikely, as not only is this quite a large amount, if someone got close they’d probably scale back, lest they cause Bitcoin to lose trust and devalue all the coins they’ve mined.
I really enjoyed working on this assignment. I think it was a great concept and I learned a lot from it. It was a little disappointing to see the submission process wasn’t more transparent, but I suppose it simply means students will get what they want out of it, there’s no medals or certificates for the ‘winners’ here anyway. I would appreciate more of a discussion in the forums of the solutions others worked on, even though it may be considered cheating for some. Perhaps with a section which only opened after you’ve submitted a passing solution? Although that didn’t prove hard…