
I finally had some time to spruce up my original Crypto SEO prototype.
If you just want to play around with it you can find it here. There’s a Guide page which explains how to use it. Also, no actual funds need be used, it’s all deployed on the test networks which don’t use real money.
Alternatively, if you’re interested in Dapp development and want to know more details about what was added and my thoughts on it, read on.
The code is all public so feel free to take a look as you’re reading.
What’s an SEO Commitment? If you’re not familiar with the original prototype, Crypto SEO allows two parties to create an agreement (SEO Commitment) whereby one party agrees to pay the other in the result that the search ranking of their site for a certain search term increases in a set amount of time. It’s intended to be a sort of pay-for-performance contract which means SEO companies only get paid for the work they put in.
Smart Contract
Automatic execution of commitment
In the prototype, in order to actually execute the commitment once the specified time had elapsed, a user would need to run the executeCommitment transaction in order to actually allocate the payouts. This seemed unecessary, so I looked at ways to automate it by executing a transaction after a set amount of time.
Whilst exploring options, I saw that there was a Chainlink job called sleep which would halt execution for a set amount of time. As I was already using Chainlink for the search result call I decided to simply add this to the existing job, to pause the request until the execution time.
Simplifying oracle jobs
When running Chainlink requests, there are core actions (like getting a webpage, parsing JSON e.t.c.), which almost all nodes should support and then there are custom ones where you can specify the server which handles that custom action (known as an adapter). For the time being the Google search request I wrote was running as a custom action where I specified my own API to fulfill the request.
When it came time to deploy on the test networks and I started to look at ways to host my Chainlink node, I realised that there are a bunch of test chainlik nodes running already. Couldn’t I just use these? Well they didn’t know how to run my custom action and I didn’t want to convince the owners to add it, but maybe I could just separate my request into core jobs? Turns out I could: most nodes allow a simple HTTP GET, and some even supported the sleep job I needed (also known as Alarm Clock).
Which was great! Not only do I not have to run my own Chainlink node, it’s also making the whole Dapp slightly more decentralized by enabling any node to fulfill the request.
LINK payment
When making calls to Chainlink Oracles, you need to pay for your request by transferring LINK tokens from the requesting contract to them. In the prototype, I skipped over this, but wanted to consider what a sustainable solution would look like.
The two obvious solutions: charge users a fee in ethereum which can be used to finance the LINK needed by the contract or ask the users to transfer the LINK to the contract directly. Because the first approach relies on maintaining the contract by constantly filling it up with LINK, I opted for the latter.
I wanted all this to happen when creating a commitment, but I needed a way to connect the separate transactions of “the user transferring LINK” to “the creation of the commitment”, so I could ensure that user had paid the required LINK fee. It turns out this is a common case in the world of ERC20 tokens - the user first runs an approve transaction allowing the contract to receive a specified amount of tokens, but NOT actually transferring. Then when the commitment creation transaction runs, it simply initiates the tranfer itself using tranferFrom, which has now been pre-approved by the user.
Tests
Ugh testing… writing them is about as interesting as watching paint dry, the only thing less exciting is documentation. But like most chores, they serve a very necessary purpose - catching mistakes at the earliest time possible.
Truffle allows tests to be written in either Solidity or Javascript. As I was going to be writing some slightly sophisticated tests that would need to simulate calls and responses to Oracles I thought Javascript was the best approach.
One thing of note when trying to test things in your contract: writing events becomes a lot more relevant. It’s a way to give the outside world a view of what’s happening on-chain.
Writing tests for each of the functions in the contract took quite a while. And when refactoring, it’s yet another time consuming chore to update them. But that said, knowing that after each change to the contract, Truffle would spin up a test chain and run a battery of tests against it in seconds gives you the warm fuzzies.
Frontend
Status Bar
A user needs to connect their wallet to a Dapp via Web3 in order to interact with it, i.e. send transactions. In order for a Dapp to get access to a user’s available accounts they need to ask the user’s permission first, it’s then handled in a dialog in the user’s wallet itself.
I originally had this handled on the same page as creating the commitment because… well there weren’t any other pages. When I started to create separate tabs for the site, I realised the status of the Web3 connection, i.e. what network they were connected to and which acccount was selected, should be displayed at the top of the page, site wide.

Modal dialogs
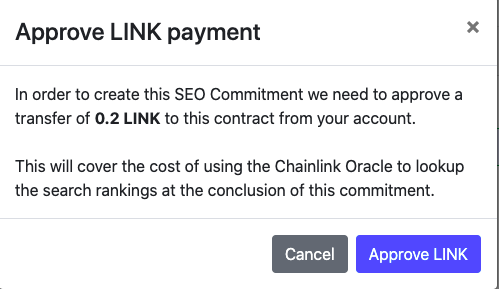
With the addition of LINK payments the commitment creation now takes two transactions. Transactions take a while to confirm and can sometimes fail, this can all take a bit of time. I wanted to give users a better sense of where they were in this process.
When creating commitments now there’s a sequence of modal dialogs which let the user know what’s happening, from asking for LINK payments:
To waiting for transactions to be confirmed:
Once the commitment has been created, a dialog helps lead them over to the View tab to see the details of the commitment they just created.
Hosting
Smart contract
The smart contract itself is just deployed to a test network for now. I chose the Kovan test network as it seemed like it was more stable. But it seems like getting test ether on Kovan isn’t easy - the faucet site is usually down. I might move everything to Rinkeby in the future.
Frontend
The site itself is hosted on my jaspa.codes server. Hosting it under a sub-domain was thankfully really easy given I’d already set up Caddy. I got HTTPS for free as Caddy automatically retrieves the required SSL certificates for any new sub-domains it sees in the conf file.
Chainlink node
I wrote above I was hoping to lean on other node operators in the test environments to run my jobs. Unfortunately, it turns out most node operators in the test environment block requests they don’t expect (most use a whitelist) and I didn’t want to rely on anyone else just to keep my Dapp accessible. So I ending up hosting my own Chainlink node anyway. A compute and SQL instance running in GCP with the Chainlink docker image was pretty quick to get set up and running.
Deployment / CI
In general I like working on the deployment and CI (continuous integration) process. The time saving benefit of automating the process is just so tangible. There’s nothing like merging new code, watching the build turn green and seeing the results deployed without touching a button. Maybe we should think the same of writing tests vs. debugging code manually…
I used Travis CI as it comes free with open source projects and I was already pretty familiar with it. In theory, Travis now does the following:
- Runs the test suite on the contract
- Deploys the google search adapter to AWS Lambda (if it changed)
- Deploys the smart contract to Kovan (if it changed)
- Deploys the frontend to
jaspa.codes
I say in theory as Truffle isn’t very good at recognizing there are changes in the smart contract, so even though it should, in reality I often deploy changes to the contract myself.
Besides the above though, I’m happy with the solution so I wanted to write about some of the details.
Usually the deployment state, which informs each step whether a new deployment is required, is only stored locally and never committed to the repository itself. To ensure I could save the state of each deployment, the deployment state is synced from/to S3 at the start/end of a successful build.
The search adapter is deployed to Lambda using a library called serverless which handles almost everything for you, from compiling the service and it’s depencies into a file stored in S3, to creating the required API Gateway endpoints to trigger the service.
There are a number of dependencies in the chain, where an output from one step is needed for another: both the frontend and the contract require the address of the search adapter, the frontend then requires the address of the latest contract, e.t.c. For this reason the order of deployment is important, as well as ensuring I’m grabbing the output of some steps and storing them in environment variables for future steps.
I looked at a number of ways to deploy the frontend to my web server. This site is deployed using Github Hooks, but that still requires me to manually push new site deployments. Ultimately, I feel like the best solution would be to sync the build to S3, then tell the server there’s an update for it to pull. The telling the server part seemed to always require SSH access though… It felt like if Travis has SSH access it may as well just rsync the build straight to the hosting directory on the server, so that’s what it does. The key for SSH access is encrypted with Travis’s CLI tool, which can encrypt files and then automatically add the decryption key as an environment variable to the repositories Travis settings. There’s also an .env file used by Truffle with secure variables (like the mnemonic for the test wallet), which is also encrypted the same way.
Wrapping up
I have essentially given zero thought to gas usage for the entire contract at the moment. Given today’s gas prices this is becoming exceedingly more important (although layer 2 solutions should help bring them down in the short term). The most pressing thing would be to refactor to reduce gas usage.
The UX isn’t always seemless on the site - certain actions take time to complete and there’s no indication to the user that something’s happening. It seems like there are also issues with the chainlink node becoming stale, where it either ignores jobs or takes a long time to execute them. More payment methods like wrapped BTC or lightning transfers would also be fun to implement.
Ultimately though, even though I think pay-for-performance smart contracts will be used more and more in the future, I’m not convinced of the business case for Crypto SEO. But it accomplished the goal I set out pretty well - learning more about Dapp development.